How to read markdown files from Next.js API routes
Next.js' API routes are handy, but they're unfortunately limited when it comes to reading static files. Here's a quick guide on how to read markdown files in a Next.js API route.

While re-building ironeko as a static site I got to the point of needing to rework how my sitemap is generated. I previously wrote about outputting XML content from Next.js' API routes and liked my solution. So we'll be sticking fairly close to that today.
All of the content on this blog is generated with Markdown files on build. This works great for articles and pages, but it presents some problems for other situations.
Understanding how Next.js builds your site
Here's a comparison of my source files vs. what files are kept after building.
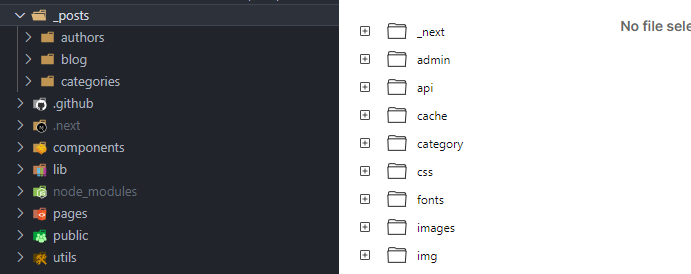
As you can see, anything that isn't inside pages or public is removed. This transformation of files is the main reason why it's impossible to read markdown files in a Next.js API route.
As I was trying to find a solution to this issue I happened upon this 'Next.js API routes should support reading files' Github issue. The suggestions mentioned in the thread range anywhere from modifying Webpack configurations to directly copying all of your markdown files to the public folder.
Copying a bunch of markdown files and making them available to the public works. However, it's definitely a less than optimal solution, so I decided to look into something more elegant.
How to work around Next.js API filesystem limitations
Personally, I think that the most elegant solution to this is to not read markdown files in a Next.js API route at all. Next.js obviously wasn't built with that in mind, and having to read and parse the contents of a folder for what could be hundreds of files will not be very performant.
So here's how you can work it, thanks to static generation.
What we can do is create a simple script whose only purpose is to fetch, parse and output static JSON of our posts. Have a look at the script below:
// lib/cache.js
const fs = require("fs");
const path = require("path");
const matter = require("gray-matter");
const getAll = dir => {
// Read files at _posts/{directory}
const directory = path.join(process.cwd(), `_posts/${dir}`);
const fileNames = fs.readdirSync(directory);
// Get the content of the files as JSON
const content = fileNames.map(fileName => {
const slug = fileName.replace(/\.md$/, "");
const fullPath = path.join(directory, fileName);
const fileContents = fs.readFileSync(fullPath, "utf8");
const matterResult = matter(fileContents);
return {
slug,
...matterResult
};
});
// Return a big array of JSON
return JSON.stringify(content);
};
const allPosts = getAll("blog");
const postFileContents = `${allPosts}`;
// Create the cache folder if it doesn't exist
try {
fs.readdirSync("public/cache");
} catch (e) {
fs.mkdirSync("public/cache");
}
// Create our cached posts JSON
fs.writeFile("public/cache/posts.json", postFileContents, err => {
if (err) return console.log(err);
console.log("Posts cached.");
});
By running this right before an npm run build it will populate the folder /public/cache with a JSON file containing all the data we decided to save to it.
This doesn't do much on its own, but let's marry this publicly available file with an API route.
// pages/api/sitemap.xml.ts
import fetch from "isomorphic-unfetch";
const sitemap = (req, res) => {
// Fetch our JSON file
const posts = await fetch(`https://example.com/cache/posts.json`).then(res =>
res.json()
);
// Do something with your data!
res.end();
}
export default sitemap;
And that's it! Do whatever you want with your data: output it as an XML or even just as plain JSON. To the layman, the output of this endpoint will look no different to an actual API.
Improving our example even further
If you're looking for even finer control, you're in luck. It's actually pretty simple.
The trick is to just make a finer cache. So rather than creating a file with all your posts, you could instead divide them up by categories, then have an API endpoint that lists JSON for each category.
This can be used for an internal search, RSS feeds, public APIs... The uses are endless!

